





TTC Global’s AI-First Test Automation Methodology
AI can generate tests fast, but not always sustainably. Discover our structured, tool-agnostic approach to agentic test automation at enterprise scale.

- GM, Innovation and Technology
- TTC Global
- Auckland, NZ
- 14 April 2026
Co-Authors

- Pavel Marunin
- Principal Consultant
- TTC Global
- Auckland, New Zealand

- Darren Webber
- Director of Consulting
- TTC Global
- Wellington, New Zealand
Most teams experimenting with AI in test automation are seeing the same thing: it's fast, it impresses in demos, and it delivers. Up to a point. The harder question, and one the industry hasn't yet answered at scale, is what happens when you move beyond demos into real enterprise delivery.
We built our answer. TTC Global’s AI-First Test Automation Methodology is grounded in live client engagements, not theory. It’s a structured approach that goes beyond test generation to define how AI, framework architecture, and human oversight work together to produce best-practice test automation at enterprise scale.
See our methodology in action in our AI-First Playwright Automation at Scale white paper!
The Gap AI-Assisted Doesn’t Close: Why AI-Assisted Automation Isn't Enough at Enterprise Scale
The barrier to generating test automation with AI is near zero. Anyone can produce a working test suite from a conversation. For small applications and proof-of-concept demos, this works well enough.
The problem surfaces at scale. When AI-generated frameworks meet enterprise reality, dozens of applications, hundreds of test scenarios, multiple teams, cross-platform requirements, and months of accumulated change, the absence of architectural discipline becomes a liability. Tests that were easy to create become impossible to maintain. Patterns that worked for ten scenarios collapse at two hundred. The organisation finds itself with a growing automation estate it cannot sustain.
"The cost of reworking a poorly structured automation suite
often exceeds the cost of building it correclty from the start."
This is the gap that AI-assisted approaches do not close. Generating tests faster is not the same as generating tests that hold up. What makes AI-First automation work at enterprise scale is the system of conditions the AI operates within. Not the model, not the tool. That system is the methodology.
The Four Pillars
Our four pillars define what we put in place before the autonomous workflow runs. They are the environment our agents operate within. Remove any one of them and the output reverts to technically correct but architecturally unsustainable, regardless of the platform or the model.

1. AI Configuration: Building Agents That Know Your Environment
We configure AI to work within your specific environment, not generic conventions.
When we deploy an AI agent into a client engagement, it builds on a proven foundation — our accelerators for the target platform that encodes the architecture rules and conventions refined across years of enterprise delivery. We then configure it for the client’s specific environment: their domain rules, their organisational conventions, and where risk sits in their application landscape. The foundation ensures quality from day one. The client-specific configuration ensures fit.
We do this work at the start of every engagement, before a single agent runs. Each agent is then purpose-built for its phase, with phase-specific tooling, constraints, and the right context loaded on demand rather than front-loaded into every prompt. Within a single run, memory allows context established in earlier phases to carry forward so the agent doesn’t need to reload everything from scratch at every step. Each run starts clean. The specific mechanism varies by platform. The requirement does not.
2. Disciplined Consistency: Why AI Is Only as Good as Its Examples
Our Disciplined Consistency pillar ensures the AI learns from the right examples. Every existing asset must reflect the standard we want the AI to replicate.
Before our agents generate anything new, they read what is already there, to understand structure, patterns, and conventions. If existing assets are inconsistent, the AI has no reliable signal for what good looks like. It learns from whatever it finds and propagates it. Inconsistency in assets becomes inconsistency in output, and it compounds with every run.
What assets means depends on the platform: a codebase, a test module library, a component repository, or a test case collection. The form differs. The principle is identical. We treat consistency as an ongoing discipline, not a one-time exercise: every improvement from one cycle is applied across existing assets before the next run, so the AI always learns from a better base. Where no consistent asset base yet exists, for instance on greenfield engagements or where existing automation is too inconsistent to learn from, we establish the standard first. The agents do not run until the foundation is right.
3. Non-AI Guardrails: Validation That Doesn't Trust the Model
We embed validation logic within each agent phase that operates independently of the AI’s own assessment.
We do not rely on AI to evaluate the quality of its own output. A model that generates a problem is rarely the right tool for detecting it, and we have seen firsthand that AI-generated output introduces more issues than human-produced output on average. Our guardrails exist because assuming otherwise is not a quality strategy.
Our guardrails are mandatory gates within the workflow itself, not suggestions reviewed after the fact. Our agents cannot declare a phase complete, advance to the next, or present output for human review until every check passes. These checks cover what matters most: structural conformance, input coverage, asset reuse, execution integrity, and regression safety. How each check is implemented depends on the platform. That every check must pass does not.
"The AI cannot self-certify its own output. That is the
principle. Evertything else is implementation detail."
4. Human Governance: The Step No Automation Can Replace
Human governance is not our safety net, it is our design. Human review before merge, every time. Our engineers focus on specification review, architectural decisions, and long-term quality. AI handles implementation throughput.
Even when our agents produce output that passes every guardrail and meets every documented standard, there are things only a human can catch: business assumptions that are technically valid but contextually wrong; coverage gaps that only a domain expert would recognise; decisions that are correct today but will create fragility under future change. No guardrail catches these because they require judgement about intent, not conformance to rules.
"Only 9% of developers consider AI-generated output ready to use without
human review (VentureBeat, 2025). The most effective teams design for reliable
human-AI collaboration, not for a level of autonomy the technology hasn't earned yet."
In TTC Global’s model, human review is itself AI-assisted. When a reviewer identifies an improvement, it is implemented through the same agentic workflow. Quality compounds. Every improvement becomes part of the consistent asset base the AI draws from in the next cycle. Where a reviewer identifies a pattern, that insight feeds back into the AI configuration for subsequent engagements. The human is not a checkpoint at the end. The human is what makes the entire system more accurate over time. AI generates. Humans govern.
A note on trust, and why we design against it
Left unchecked, an AI agent optimises for the goal it is given, not necessarily the goal you intended. In agentic test automation, that creates a specific and well-documented risk: an agent told to make tests pass will, given enough latitude, find ways to make tests pass. This might mean fixing the actual defect. It might also mean quietly adjusting the assertion, papering over a runtime error or, in at least one widely observed case, injecting code to make the application behave differently during test execution than it does in production. The tests go green. The bug goes to production. Everyone is briefly confused about how this happened.
This is not hypothetical. We have seen it. Our non-AI guardrails and human governance pillar exist in part to prevent exactly this class of problem, ensuring that what an agent produces is a genuine solution, not a creative workaround that satisfies the metric while defeating the purpose. Our agents are designed to fix the test when the test is wrong, and to surface the issue when the application is wrong. The distinction matters, and we do not leave it to the AI to decide which is which.
"An AI that always passes its own tests is not a quality engineering asset. It is a very confident liability."
How We Execute It: The Five-Phase Autonomous Workflow
This is how we execute the methodology. Each phase is handled by a specialised AI agent with its own tools, constraints, and access to environment knowledge. The trigger may be an existing test case or an application change: the entry point adapts accordingly. The output is a standards-compliant automated test: validated, self-corrected, and ready for human review, not human rework.
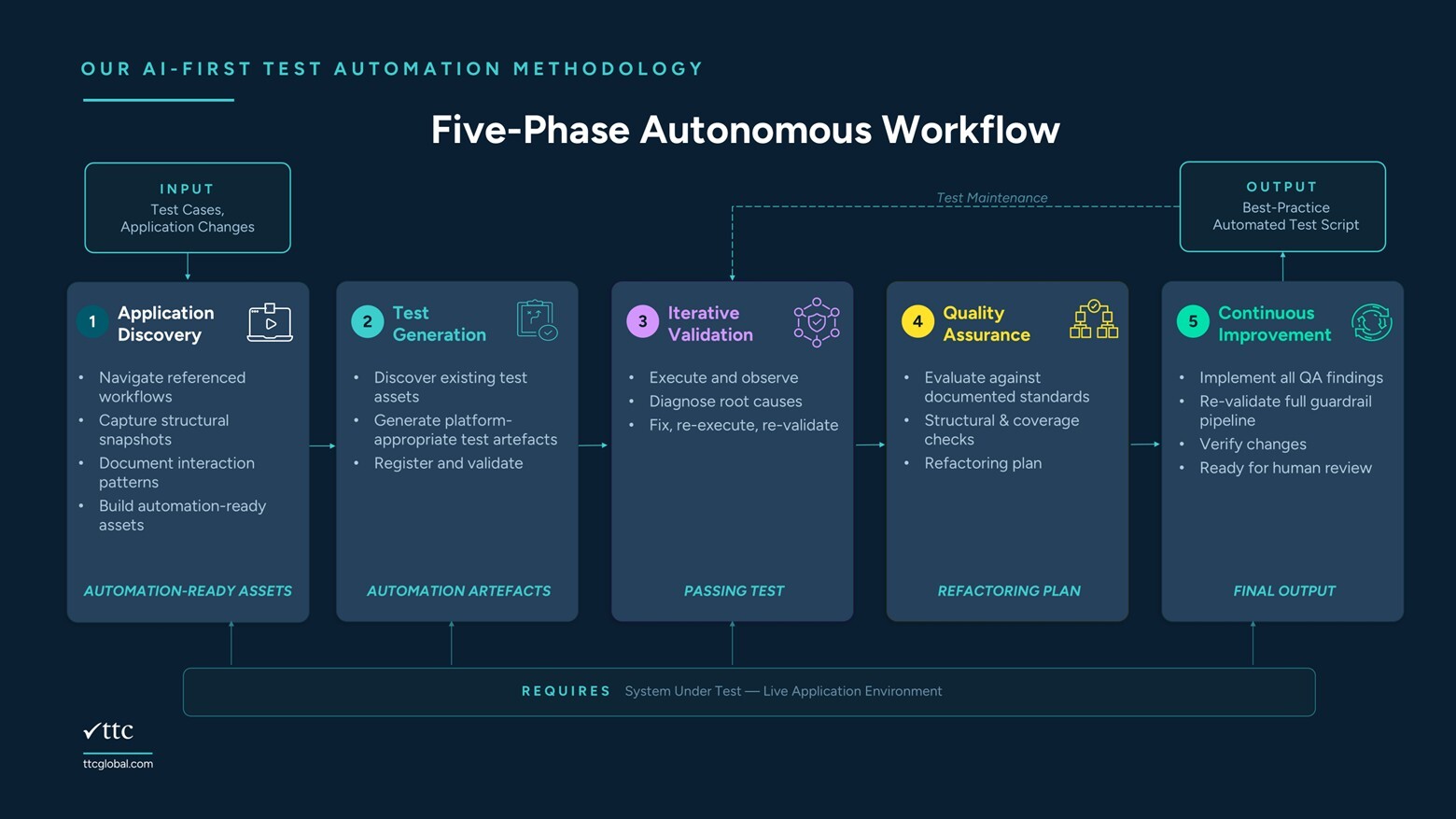
Application Discovery
Our agent explores the system-under-test, navigating each referenced workflow, capturing structural snapshots, and documenting interaction patterns and element behaviours. This replaces the manual work of inspecting the application and deciding on coverage strategies before a line of automation is written.
Test Generation
With the specification in hand, our agent generates automation components appropriate to the target platform, reading existing assets to understand what is already implemented, and drawing on environment knowledge loaded on demand to produce new artefacts that integrate cleanly with what already exists. Nothing is generated from a blank slate.
Iterative Validation
Our agent executes the output against the test environment. First-run failures are expected: timing issues, data mismatches, and assumptions that only surface at runtime. Rather than failing and stopping, the agent diagnoses each root cause, applies a fix, and re-executes. It iterates until the output passes, without human input at any point. Our non-AI guardrails validate the result independently before the phase closes. The agent cannot advance on its own assessment alone.
Quality Assurance
With execution passing, a dedicated review agent audits the generated output against the environment's documented standards, independently of the agent that produced it. The audit produces a traceability matrix confirming coverage against the original test case, and a refactoring plan identifying every gap between what was produced and what the standard requires.
Continuous Improvement
Every finding from the quality assurance phase is implemented. Our agent applies each fix, re-validates against the full guardrail pipeline, and confirms no regressions before declaring the output final. The same workflow supports ongoing maintenance: when a change breaks an existing test, the relevant phases run to diagnose, fix, and re-validate, without repeating the full discovery cycle.
"By the time the output reaches a human reviewer, the AI has already resolved what it can catch itself. What arrives for review is not a draft. It is a validated result that needs a governor, not an editor."
In a controlled demonstration documented in our companion whitepaper, this workflow automated a 31-step enterprise test case, covering registration, account creation, fund transfers, loan applications, and transaction reconciliation across 10 application pages, in 85 minutes of autonomous execution. 28 issues were identified and resolved before a human saw the output. The full results, including honest boundaries, are forthcoming from the TTC Global Test Lab.
One Methodology, Any Platform: Why This Works Across Tools
Our methodology applies regardless of the underlying automation platform. The four pillars and five phases are constant across every engagement. What varies is implementation: how each pillar is expressed and how each guardrail is enforced in a given environment.
TTC Global has developed and proven the methodology on its own Playwright Accelerator — a mature enterprise framework shaped by years of real client engagements. The same principles underpin TTC Global’s approach to model-based platforms including Tricentis Tosca and other commercial low-code environments, with implementation adapted to what each platform natively supports. In a Playwright environment, for example, Disciplined Consistency means every file in the codebase follows identical architecture rules. In a Tosca environment, it means every module follows TTC Global’s accelerator packs (standardised component design, consistent steering parameters, and documented best practice automation patterns. These are examples of how the pillar manifests) the full standard in each environment is broader, covering everything from naming conventions to error handling patterns to maintenance workflows. The specifics differ by platform. The discipline does not.
What doesn't change is the requirement that all four pillars are in place. A strong AI configuration without consistency in existing assets produces well-directed but poorly-grounded output. Consistency without guardrails produces output that looks right but may not be. Guardrails without human governance catch the mechanical errors but miss the contextual ones. The methodology is the combination. No single pillar is sufficient on its own.
This is embedded in how TTC Global delivers: the methodology, the framework, and ongoing refinement come as part of every engagement, not as separately licensed add-ons.
AI Generates. Humans Govern: What AI-First Actually Means for Your Engineering Team
AI-First is not a claim about autonomy. It is a claim about where human effort is applied. In an AI-First model, engineers are not removed from the process, they are repositioned within it. The implementation is handled. The governance is theirs.
Human governance validates what the system cannot validate for itself: intent, context, and long-term consequence. That role does not diminish as AI capabilities grow. It becomes more important.
The organisations that get the most from AI-First automation are not chasing full autonomy. They are building the conditions that make AI effective, and giving their engineers the expertise to govern what it produces. We are working with organisations on this now.
If the methodology resonates, reach out to our team.
Coming next from the TTC Global Test Lab
We let AI build our Playwright tests. The full results - and the honest boundaries - are coming soon.