






- 27 October 2022
Introduction
Every automation project presents its unique challenges, and the recent big data initiative one of our clients has embarked on is no exception. The project is part of a large-scale enterprise-wide digital and business transformation that, among other things, involved the implementation of a new Extract, Transform and Load (ETL) data pipeline. Multiple external vendors would offload large volumes of data in vendor-specific format into the landing zone called Raw bucket. The in-house data pipeline would then process each vendor’s data between Raw, Clean and Curated states into a Unified Data Model to prepare it for analysis and reporting downstream. The author was tasked with automating test scenarios for the data pipeline between Raw, Clean and Curated states.
As with any large and complex project, some of the requirements were not immediately clear from the outset, the solution design had to change several times during implementation, and multiple issues with the data at source were uncovered throughout the project timeline. Because of these issues, at the later stages of the project it became apparent that the original test design, which involved validating Raw to Clean to Curated data transformation steps on random samples of real data was not fit for purpose. It was necessary to implement a robust automation solution that would ensure reliable and reproducible test results that validated the entire dataset in a certain time interval. That was easier said than done, though, because even with a small number of data sources in the pilot project, the dataset could easily run into millions of records. The second challenge had to do with the fact that the solution encompassed two different vendors with the data stored in different databases at source: Dremio data lake and Amazon S3. This required multiple database driver implementations for data access and severely complicated test automation, because native row types from different database drivers were not comparable directly, and result set iteration implementations varied greatly between the drivers as well.
And herein lay an opportunity to design and implement a database test automation framework that would encapsulate the complexities of accessing multiple relational databases and comparing SQL result sets between them at the required scale efficiently enough to make daily regression test runs on full datasets feasible. This article describes the requirements that the DB framework must fulfil, its architecture and usage guidelines, as well as the automation benefits it helped achieve and future extension potential.
Requirements

- Between databases
- Between tables
- Between a table and a hardcoded dataset
The primary motivation for the DB framework implementation was to abstract the test scripts away from different row types and result set iteration logic supported by different database drivers natively and provide reusable methods for SQL result set comparison that can be relied on by automated tests to compare query results from the same or different databases at scale. New abstraction layers were required to achieve separation of complexity between business logic validation in the test scripts and the technicalities involved in establishing the database connection, authentication, and iteration over SQL result sets. The fact that two different relational databases, Dremio and Amazon Athena, had to be supported that do not allow direct result set comparison due to inconsistent native column types and iteration logic, made a separate framework even more appropriate for this purpose.

Creation of a new framework to deal with SQL result sets would also enable the result set validation to be optimised for performance and tuned on large datasets in separation from the functional test scripts themselves, which would reduce the overall solution complexity. Once the framework has been created and integrated into the test scripts, any further maintenance can be carried out without changing the test code.

To achieve the most benefit, the DB framework would need to support further extension and reuse on other projects that also require database result set comparison. To this end, modular architecture was required to future-proof the solution.

The DB framework needed to integrate into the existing open-source tools ecosystem already present on the project. It had to be written in Java like all the other in-house automation frameworks and rely on relevant software development kits for database access, without leveraging any proprietary tools.
Architecture
The code was written in Java to ensure consistency with other automation frameworks used in the project. To achieve the stated objectives, a modular framework architecture was designed. The following layers of abstraction were implemented:
- One abstract parent class that represents SQL result set as a generic collection and implements comparison and validation methods in a database-agnostic way
- A generic query class per supported database type to handle database-specific query execution and iteration
- A custom iterator class per database to return one next element in a generic format
- A custom DB connection class per database to handle DB connection and query execution
Representing each query result set as a collection not only enables seamless comparison of result sets between any supported databases, but also with any other collections, such as hardcoded Cucumber data tables, which are commonly used in test scripts to describe expected results.
To achieve consistency between databases, each database-specific iterator converts each row to a map of strings and returns one row at a time. This generic row representation was chosen for easy integration with Cucumber data tables from test scripts but has a drawback: column type information is lost at conversion into a string map. For example, an integer value of 1 and a string value of “1” will be indistinguishable after conversion. While this information is significant, implementing a database-independent column type representation that can capture all the possible nuances across all databases is a monumental task that cannot be easily justified, given that an easy workaround exists, which allows to validate column types and maintain test coverage even with a string map row representation. To this end, one can simply write a SQL query that selects all rows for a specific table from the database schema, hardcode the result set in a Cucumber data table, and implement a regression test that validates the table schema against a hardcoded collection using the same query. With this approach the string map representation of result set rows does not create any impediments for test coverage.
It is important to note that in the interest of performance of the DB framework over large datasets that can potentially contain millions of rows, the full query result set is not stored anywhere at runtime. Instead, database-specific iterators are implemented that return only one next row at a time. These iterators are used to synchronize two result sets that are being compared, therefore, ordering both result sets on the same columns in the respective queries is essential to ensure reliable comparison results.
Using the DB framework in test automation projects is easy and requires the following steps:
- Import the framework dependency
- Configure the required database connections using the provided classes
- Extend abstract database-specific queries to define concrete queries with parameterized SQL query strings for each test case as needed
Two methods are provided by the framework to compare the given result set with another collection and to validate the given result set against a list of business rules. When either method is invoked, the query will be executed and the result set compared or validated accordingly, leaving the test automation engineer involved in test implementation and execution to focus on the business logic complexity involved in specific test cases, rather than the intricacies of type conversion and consistent iteration. Should the business logic in question be sophisticated, custom comparison or validation functions can be defined for some test cases as needed and passed as parameters to the framework methods from the parent class.
Benefits
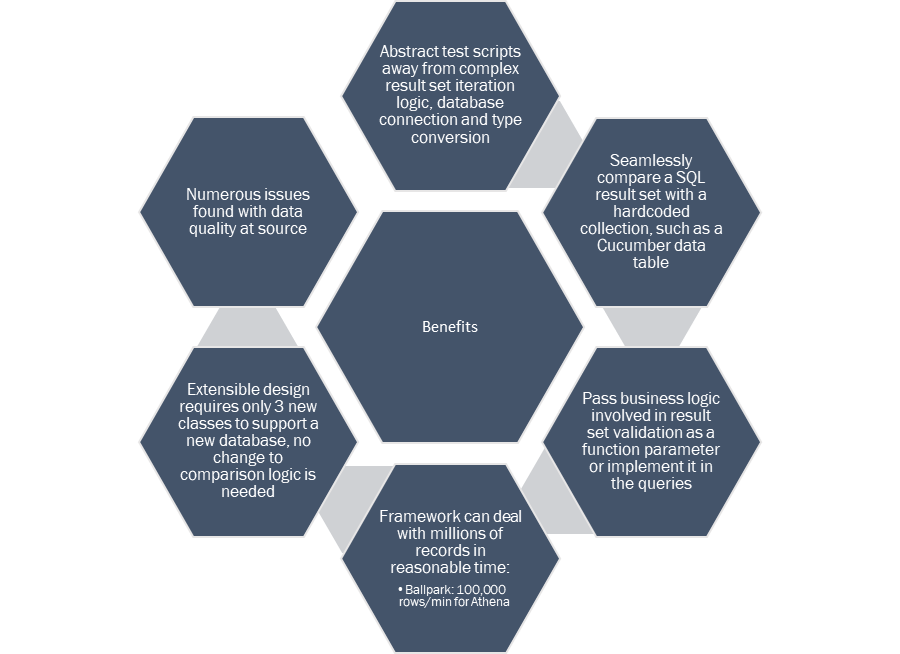
The DB framework was designed to solve a complex technical challenge of comparing two SQL result sets from different relational databases that cannot be done directly due to different result set iteration logic and incompatible native row types inherent in different database drivers. This was achieved by implementing standardized iterators for each supported database type and converting all rows in the result set into a generic type.
Another key benefit the DB framework provides is support for a common use case in test design that involves comparing the actual result against a hardcoded expected value. To this end, query result sets are treated as generic collections and can be compared not only to other query result sets from any supported database, but also to any other collections, such as hardcoded Cucumber data tables.
The business logic involved in the result set comparison can either be implemented in the source and target queries themselves or encapsulated into a Java function and passed into the DB framework’s result set comparison method as a function parameter, which the framework will apply to each pair of rows to determine the overall comparison outcome. Thus, the test automation engineer involved in test implementation and execution can choose either comparison logic implementation method that best suits their needs. Custom validator functions can also be passed as the parameter into the framework’s validation method, which helps cover a common data validation use case that makes sure each column value in the result set conforms to specific business constraints.
The DB framework was implemented with efficiency on large datasets in mind and is suitable for comparison and validation of millions of rows per query. While actual execution time will depend on many factors, comparing two result sets from different cloud-based Athena tables containing 3,345,058 rows each on a mid-range Windows laptop running a single test case in one thread took 35 min 18 sec at the time of writing, suggesting about 100,000 rows/min processing speed. One of the two tables used in the queries in question utilized AWS Glue table partitions in the where clause with partition indexing and partition filtering enabled to improve query performance, but the other one did not. Both queries completed execution in about a minute, with the rest of the time being spent on query result set iteration and validation. The execution time can be improved significantly in a continuous integration pipeline that has more computing and networking resources. Since the full result set is never stored in memory, there is no upper limit on the total number of rows the framework can handle.
The framework is extensible by design and can easily accommodate new database types if required. Adding support for a new database type to the framework will only require the implementation of 3 new classes to deal with database connection, result set iteration and type conversion. There is no need to implement the result set comparison logic again, because this functionality is already implemented in the abstract parent class based on string map iterators in a database-agnostic way. An added benefit of this architecture is that the result sets from the new database can be compared to any other result sets supported by the DB framework or even hardcoded collections, such as a Cucumber data table, out of the box without any extra work. It is therefore very easy to introduce the DB framework in any test automation project that requires database result set comparison or validation.
Conclusion
Big data presents significant challenges for test automation. The ETL data pipeline in one of our client’s projects processed large amounts of data that had to be validated against business rules in automated regression test scripts. The pre-existing scripts were not efficient enough to validate millions of rows of data in reasonable time and had to rely on random sampling instead, which made test results unreliable. Low trust in data quality at source provided extra motivation to validate the entire dataset. Furthermore, result sets from two different databases had to be compared for data validation, making direct row comparison impossible due to different native column types and iteration logic, which presented a major technical challenge in its own right. Implementation of a new database test automation framework was therefore required to address these challenges, which this document has described in detail.
A modular framework architecture was designed to separate complexity into several abstraction layers that enabled easy code reuse and maintenance. The primary design objectives included high performance on large datasets, convenience of use in test automation projects and easy extensibility to add support for other database types in the future. The framework achieved its objectives and provided significant benefits to the project by reducing the test implementation complexity, increasing test coverage by enabling full result set validation, as opposed to random samples, and ensuring acceptable test execution times even on datasets containing millions of records.
With only minimal configuration, the framework is easy to integrate into new test automation projects. Extension to support new databases is also easy, with only 3 new classes required for each new database. The core result set comparison and validation logic are implemented on abstract iterators and can be used to compare result sets between any supported database types or hardcoded collections without any changes.