





Architect-Guided AI: How We Built a Java Automation Framework 7x Faster
How architectural oversight and an AI agent swarm rebuilt a scalable Java automation framework 7x faster, showing where AI accelerates development and where humans remain essential.

- Principal Consultant
- TTC Global
- Auckland, New Zealand
- 19 November 2025
Building large-scale test automation frameworks has always been a slow and complex task. Until now. By pairing architectural discipline with a multi-agent AI swarm, our team rebuilt an advanced Java automation framework in a single week. The result: a lean, streaming-first solution capable of comparing millions of rows across JDBC, LDAP, CSV, and API sources without running out of memory. Along the way, we discovered what AI can and can’t do when left to its own devices, from brilliant optimizations to baffling abstractions, and how human architectural oversight remains the key ingredient in turning AI speed into real-world results.
A Whole New World: Architect-Guided AI Framework Development

(Yes, we used ChatGPT to generate this image)
We recently resurrected a Java database automation framework we had originally designed and implemented for a client a few years ago. When another client suddenly made a dramatic pivot and needed to compare datasets between different sources, we knew exactly what was required: a sophisticated tool for cross-database result set comparison at scale.
The new framework shares a similar public API with its predecessor but was redesigned and reimplemented from the ground up to meet challenging new requirements. It needed to support JDBC, LDAP, CSV, and API result sets with sophisticated authentication and pagination, while remaining lightweight enough to import into Katalon 10, the client's tool of choice. The core technical challenge was handling millions of rows without running out of memory, requiring a streaming-first architecture where all data processing uses iterators that maintain O(1) memory complexity regardless of dataset size.
The framework features a modular, extensible design with comprehensive unit and integration tests that interact with databases in Docker containers and API mocks. It has only one production dependency for JSON parsing. Everything else is pure Java 11 to prevent dependency conflicts in Katalon.
We built the entire framework in just one week, a result that surprised even us.
Claude estimated that this would have taken a senior automation architect up to seven weeks without AI—representing a 7x time savings.
Solution Architecture
Architecture Overview
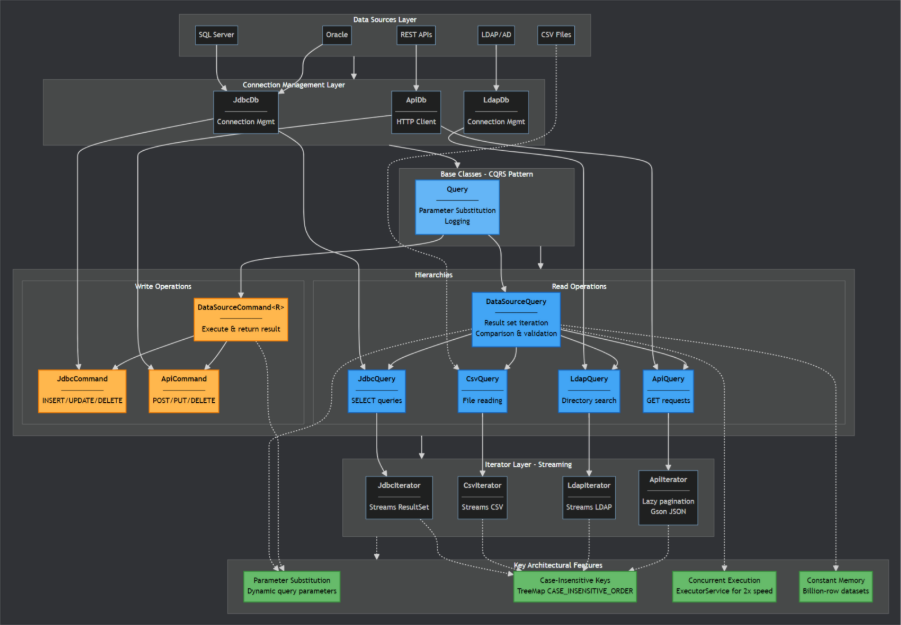
Figure 1. Architecture Overview
The framework uses a dual-hierarchy CQRS (Command Query Responsibility Segregation) architecture that separates read operations (Query classes) from write operations (Command classes). This separation allows queries to focus on memory-efficient data retrieval and comparison, while commands handle database modifications with appropriate return types for each operation. All queries implement Iterable<Map<String, String>> for memory-efficient iteration. The design supports concurrent execution via ExecutorService, case-insensitive column mapping for cross-database compatibility, and parameter substitution for dynamic queries. With only a single production dependency (Gson for JSON parsing), the framework maintains a lightweight footprint suitable for integration into existing automation tools like Katalon whilst handling million-row comparisons in constant memory.
The architecture tackles three major issues that make cross-system dataset comparisons difficult.
Memory Efficiency
Traditional approaches load entire result sets into memory before processing. That is fine for small datasets but impossible when dealing with millions of rows. Loading a million-row result set into memory will exhaust available heap space and crash the JVM.
We implemented a streaming architecture using the Iterator pattern where all data processing happens row-by-row without ever loading complete result sets. Each query type (JDBC, CSV, LDAP, API) returns an iterator that maintains O(1) memory complexity regardless of dataset size. This means comparing 1,000 rows or 1 million rows uses the same amount of memory. The framework can validate million-row datasets in constant memory, processing data progressively as it arrives rather than buffering entire result sets.
Concurrent Query Execution
Sequential execution — run query one, wait for completion, run query two, then compare — wastes significant time, particularly with slow network connections or complex database queries. The total time becomes the sum of both query execution times plus comparison overhead.
The framework executes both queries concurrently using an ExecutorService. While one database fetches its next batch of rows, the other does the same in parallel, and the comparison happens as results arrive. This concurrent approach reduces total time to approximately max(query1_time, query2_time) rather than their sum, roughly doubling performance for most comparisons. The implementation includes proper error handling and resource cleanup even when exceptions occur.
Cross-Database Compatibility
Different systems use different naming conventions: SQL Server stores CustomerId, while Oracle uses CUSTOMER_ID. When comparing across heterogeneous sources, these naming inconsistencies cause false failures even when the underlying data is identical.
The framework implements case-insensitive column matching throughout by using TreeMap with String.CASE_INSENSITIVE_ORDER for all result maps. This eliminates false failures from casing differences and provides a consistent interface across JDBC, CSV, LDAP, and REST API data sources. No manual case normalisation is required in comparison logic.
Architect-Guided AI Development: A New Paradigm
What makes this project particularly interesting is that it represents our first sophisticated test automation framework built entirely by an AI agent swarm in Claude Code, with our guidance. We started with the old codebase from the original framework, which had broken external dependencies, no unit tests, and only a fraction of the required functionality. However, having designed the original framework and seen it deployed on a real project, we knew exactly what we wanted to achieve and what good looked like. As it turned out, this was the key to success.
The Development Approach
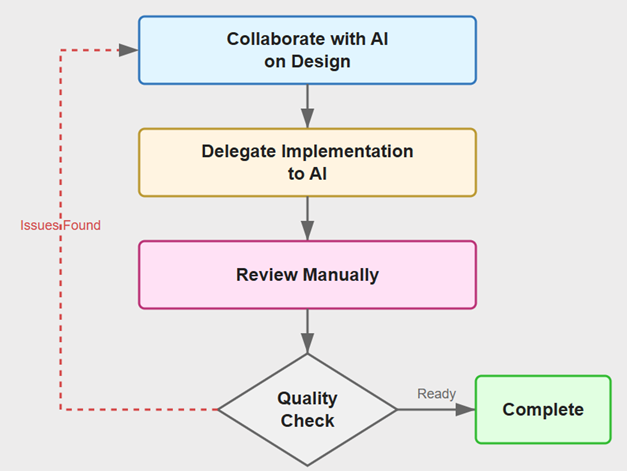
Figure 2. Architect-Guided AI Development
Architect-Guided AI Development is a fundamentally new way of creating software where an experienced architect guides AI agents through iterative design and implementation cycles. Rather than writing code directly, the architect defines requirements, reviews architectural plans, validates implementations, and provides corrections when the AI deviates from good design principles. The workflow forms a continuous loop:
Architect collaborates with AI to design the solution, specifying requirements and architectural constraints
AI implements the design, writing code, tests, and documentation
Architect reviews the implementation, identifying issues and providing guidance
Loop repeats until the solution meets quality standards
It combines the AI’s implementation speed with the architect’s hands-on control of the design. We didn't write a single line of code ourselves and even learned a few things from the AI along the way.
The Agent Swarm Configuration

Figure 3. AI Agent Swarm
We implemented this approach using a two-agent swarm with distinct, complementary responsibilities:
The architecture-coordinator agent acted as an elite software architect, ensuring all components adhered to streaming-first design principles and memory-efficient patterns. It was responsible for creating implementation plans, validating architectural compliance, and orchestrating the development workflow. Critically, it was configured to always present plans for our review and approval before proceeding, preventing the AI from charging ahead with implementations that might not align with our vision.
The java-implementation-dev agent served as an expert Java developer, translating architectural plans into working code, writing comprehensive unit tests, and maintaining documentation. This agent focused purely on implementation quality (code style, test coverage, and documentation) whilst the architecture-coordinator ensured structural soundness.
This separation of concerns (architectural oversight versus implementation) proved essential for maintaining quality and consistency throughout the project. The architecture-coordinator would propose a design, we'd review and adjust it, then the java-implementation-dev would implement it whilst the architecture-coordinator monitored for architectural compliance.
Why Architectural Oversight Is Essential
However, there are many AI-specific challenges that need solving. AI has tunnel vision and a short memory and is prone to assumptions and hallucinations. It's essential for the person guiding it to know exactly what good looks like and what the end result needs to be.
For example, the AI designed and implemented an effective API result set comparison solution and integrated it into the framework as prompted. It worked, but it also created a useless abstraction layer for no reason. When we pointed this out, the AI agreed and removed it.
Then we noticed the test files had grown to over 1,500 lines because we hadn't explicitly instructed the AI to manage file size, so it kept quietly expanding existing files beyond reason. The AI immediately acknowledged the problem and proposed a top-to-bottom redesign of the unit test approach. The design looked good, but the task proved too large. By the time it finished, everything worked again, but there was an entire package full of unused abstractions. The AI had forgotten about them and changed approach midway. We pointed this out, and it removed the unnecessary code and standardised the design throughout. Then we discovered a Python script called fix_tests.py in our Java repository that the AI had decided to create. It worked, apparently. But Python! And so, the loop continued.
When AI Helps (and When It Doesn't)
In another example, the AI demonstrated both its debugging potential and its limitations. After pushing a big change, the build failed two unit tests in the pipeline, though they'd passed locally. We examined the test log: it looked fine, so we copied the error message and asked the AI to investigate.
It identified the issue: we were running the build on an old commit because the error message contained the old test name. This made no sense: the pipeline triggered automatically on the latest commit, and the test name was correct. Pure hallucination.
We reset the context and tried the same prompt again. The AI identified a new issue: the pipeline container had leftover state and needed pruning. Again, off target. Microsoft-hosted Ubuntu agents start with a clean state, so there's nothing to clean up before the test run. Another hallucination.
For our third attempt, we carefully extracted the full log for the failed test, put it in a file, and asked the AI to investigate. This time, the AI identified a race condition between different unit tests that read and wrote to the same table in the same database in parallel, corrupting each other's state. This made total sense: it was the actual root cause!
We asked it to fix the issue, and the AI proposed a sophisticated solution with sequential test runs and elaborate state cleanup between them. Sure, it would work, but why not simply write to a different table than you're reading from? The AI immediately embraced this simpler approach and implemented it. Issue fixed, tests pass. But did the AI help or hinder?
Why Human Oversight Still Matters in AI-Driven Engineering
This project still required a ton of work even though the AI wrote all the code. We ended up with a much bigger and better framework than the original. The new framework was packaged into a JAR and imported into Katalon as required. With this approach we were able to successfully demonstrate to the client the feasibility of this approach to compare result sets across heterogeneous sources at the required scale. So, we have succeeded where previous attempts had failed, and the client allowed us to proceed to subsequent stages in the project delivery.
But we only achieved a good result because we repeatedly stopped the AI from going astray by reviewing each implementation step and providing guidance.
On the other hand, we completed this new framework in just one week. True, we didn't start from scratch, but there's no way we could have done this in the time we had without an agentic AI swarm helping us design the solution and write the code. Claude estimated that this framework would have taken a senior automation architect up to seven weeks to build without AI. That estimate seems reasonable (not to say optimistic) given the complexity, representing 7x time savings. For reference, the original much smaller framework took us about three months without AI, including design, implementation and validation on a real project.
Agentic AI swarms and Claude Code appear to offer astronomical ROI when used by someone who understands good architecture. Our experience shows that without strong architectural guidance, AI-driven development can quickly go off course: a complex mix of architectural patterns (even languages) that initially works somehow, until it becomes too expensive to maintain and scale, even with AI assistance. This is yet another argument for keeping a suitably qualified human in the loop to reap the full benefits of AI.
Read OUR OTHER Test Lab Blogs
We'll be publishing our R&D under Test Lab!
To get insights sent to your inbox or additional information about our Test Lab innovations, submit this interest form.
Browse our other experiments below: